L'authentification par mot de passe demeure l'un des mécanismes de contrôle d'accès les plus largement déployés dans les infrastructures critiques civiles et scientifiques. L'augmentation rapide des capacités de calcul, combinée aux progrès des modèles d'intelligence artificielle, réduit significativement la durée de vie opérationnelle de schémas historiquement jugés sûrs.
L'authentification par mot de passe demeure l'un des mécanismes de contrôle d'accès les plus largement déployés dans les infrastructures critiques civiles et scientifiques. Cependant, l'augmentation rapide des capacités de calcul, combinée aux progrès des modèles d'intelligence artificielle appliqués à l'optimisation des attaques, réduit significativement la durée de vie opérationnelle de schémas historiquement jugés sûrs. Cette étude présente une analyse quantitative de ces évolutions et examine les ajustements progressifs mis en œuvre dans les politiques internes de l'IFRAS.
Les premiers systèmes d'authentification informatisés, déployés à grande échelle à partir des années 1980 et 1990, ont été conçus dans un contexte technologique et opérationnel très différent de celui d'aujourd'hui. Les modèles de menace alors retenus reposaient principalement sur l'idée que l'attaquant devait disposer soit d'un accès physique prolongé aux machines, soit de ressources matérielles lourdes, coûteuses et rares. Les attaques à distance étaient limitées par la faible interconnexion des systèmes, l'absence d'Internet grand public et des débits réseau très réduits.
Dans les environnements institutionnels de l'époque (universités, administrations, grandes entreprises), les systèmes étaient majoritairement fermés, centralisés et administrés localement. Les comptes utilisateurs étaient hébergés sur des mainframes ou des serveurs Unix partagés, accessibles depuis des terminaux internes. Dans ce cadre, le risque principal était l'usurpation par un utilisateur légitime ou la compromission locale, bien plus que l'attaque automatisée à grande échelle. C'est dans ce contexte que les politiques de mots de passe ont été définies. Des schémas courts, combinant lettres et chiffres sur une longueur limitée (souvent 6 à 8 caractères), étaient considérés comme suffisants. Cette perception était renforcée par les contraintes d'ergonomie (claviers de terminaux, mémorisation humaine) et par le coût des attaques par force brute.

Au début des années 2000, un tel espace de recherche dépassait largement les capacités de calcul accessibles dans un cadre réaliste. Les processeurs grand public fonctionnaient à quelques centaines de MHz, et les architectures parallèles restaient réservées à des centres de calcul spécialisés. Une attaque exhaustive sur un tel espace pouvait théoriquement nécessiter des années, voire des décennies, même en supposant une vérification rapide des tentatives. De plus, les mécanismes de stockage des mots de passe reposaient souvent sur des fonctions de hachage cryptographique conçues pour être relativement coûteuses en calcul (comme DES-based crypt, puis MD5 ou SHA-1 dans certains contextes), ce qui ralentissait encore les tentatives hors ligne. La combinaison d'un espace de recherche large, d'une puissance de calcul limitée et d'un faible niveau d'exposition réseau rendait donc ces schémas acceptables au regard des risques perçus.
Cependant, ces hypothèses se sont progressivement effondrées avec la généralisation d'Internet, l'explosion de la puissance de calcul (CPU multicœurs, GPU, ASIC), la démocratisation du calcul distribué et l'industrialisation des attaques automatisées. Ce qui constituait autrefois une barrière économique ou technique est devenu aujourd'hui trivialement accessible, rendant obsolètes les modèles de sécurité hérités de cette période. Mais alors, comment bien se protéger et être certains de la robustesse de son mot de passe ?
Il existe plusieurs catégories d'attaques visant à compromettre les mécanismes d'authentification par mot de passe, chacune exploitant des leviers techniques, statistiques ou humains distincts.
Dans une analyse strictement cryptographique, excluant les faiblesses humaines et les compromissions système, le vecteur d'attaque le plus dominant reste la force brute. Ce sont donc ces approches qui constituent les principales références pour l'évaluation quantitative de la robustesse des mots de passe.
Premièrement, nous devons définir la notion de « force » d'un mot de passe : on désigne communément par la « force » d'un mot de passe sa capacité à résister à une attaque par énumération exhaustive, plus connue sous le nom d'attaque par force brute. Ce type d'attaque consiste à tester systématiquement toutes les combinaisons possibles jusqu'à trouver la bonne. D'un point de vue conceptuel, la force d'un mot de passe peut être rapprochée de celle d'un mécanisme cryptographique : elle est comparable à la taille d'une clé de chiffrement. Plus cette « clé » est grande, plus l'effort nécessaire pour la casser augmente.
La robustesse d'un mot de passe est généralement exprimée à l'aide de l'entropie de Shannon, mesurée en bits. Cette mesure permet de quantifier l'imprévisibilité d'un mot de passe de manière compacte, sans avoir à manipuler directement des nombres de combinaisons souvent astronomiques. L'entropie représente la quantité d'information nécessaire pour deviner un mot de passe choisi aléatoirement dans un ensemble donné. Plus l'entropie est élevée, plus le mot de passe est théoriquement difficile à deviner. Cependant, il est crucial de souligner que l'entropie n'est qu'une mesure théorique. Un mot de passe peut afficher une entropie élevée sur le papier tout en étant extrêmement faible en pratique. Par exemple, "Password123*" respecte de nombreuses règles de complexité (majuscules, minuscules, chiffres, caractères spéciaux), mais reste trivial à casser car il repose sur des motifs humains largement intégrés aux dictionnaires d'attaque modernes. C'est pourquoi la génération réellement aléatoire des mots de passe est un facteur déterminant de leur sécurité effective.
Cette entropie se calcule à partir de la longueur du mot de passe (L), ainsi que la taille du jeu de caractères utilisé (B), aussi appelée pool. La formule est la suivante :
Voici un tableau représentant l'entropie de différents mots de passe en fonction du nombre de caractères utilisés et du nombre de pools possibles :
| Base / Longueur | 8 caractères | 12 caractères | 15 caractères | 18 caractères |
|---|---|---|---|---|
| Base 10(chiffres) | 26 bits | 39 bits | 49 bits | 59 bits |
| Base 26(minuscules) | 37 bits | 56 bits | 70 bits | 84 bits |
| Base 36(minuscules + chiffres) | 41 bits | 62 bits | 77 bits | 93 bits |
| Base 52(min. + maj.) | 45 bits | 68 bits | 85 bits | 102 bits |
| Base 62(min. + maj. + chiffres) | 47 bits | 71 bits | 89 bits | 107 bits |
| Base 85(alphabet étendu + spéciaux) | 51 bits | 77 bits | 96 bits | 115 bits |
Nous avons donc une première mesure possible d'estimation de robustesse d'un mot de passe. Ceci étant dit, il est possible de développer légèrement ces équations. En effet, on peut déterminer le nombre total de combinaisons possibles par la formule :
Voici le même tableau, mais représentant cette fois le nombre total de combinaisons possibles :
| Base / Longueur | 8 caractères | 12 caractères | 15 caractères | 18 caractères |
|---|---|---|---|---|
| Base 10(chiffres) | 100 000 000 | 1,00e+12 | 1,00e+15 | 1,00e+18 |
| Base 26(minuscules) | 2,09e+11 | 9,54e+16 | 1,67e+21 | 2,94e+25 |
| Base 36(minuscules + chiffres) | 2,82e+12 | 4,73e+18 | 2,21e+23 | 1,03e+28 |
| Base 52(min. + maj.) | 5,35e+13 | 3,90e+20 | 5,49e+25 | 7,72e+30 |
| Base 62(min. + maj. + chiffres) | 2,18e+14 | 3,22e+21 | 7,68e+26 | 1,83e+32 |
| Base 85(alphabet étendu + spéciaux) | 2,04e+15 | 9,24e+22 | 5,09e+28 | 2,80e+34 |
Par conséquent, nous pouvons relier ce nombre avec l'entropie dans une seule et même équation :
Nous pouvons, grâce à cette entropie, en déduire le temps estimé de cassage. La complexité d'un mot de passe prend tout son sens lorsqu'on la relie à un temps de cassage estimé. Celui-ci dépend non seulement de l'entropie, mais aussi de la puissance de calcul disponible pour l'attaquant. Une estimation simplifiée du temps nécessaire pour casser un mot de passe est donnée par la formule :
En réutilisant les deux mêmes tableaux utilisés précédemment, voici l'estimation du temps qu'il faudrait pour déchiffrer un mot de passe, avec une valeur arbitraire d'un milliard de tentatives par seconde (ce qui est déjà énorme) :
| Base / Longueur | 8 caractères | 12 caractères | 15 caractères | 18 caractères |
|---|---|---|---|---|
| Base 10(chiffres) | Instantanément | 17 minutes | 12 jours | 3,17e+1 années |
| Base 26(minuscules) | 3 minutes | 3,03 années | 5,32e+4 années | Éternité |
| Base 36(min. + chiffres) | 47 minutes | 1,50e+2 années | 7,01e+6 années | Éternité |
| Base 52(min. + maj.) | 15 heures | 1,24e+4 années | Éternité | Éternité |
| Base 62(min. + maj. + chiffres) | 3 jours | 1,02e+5 années | Éternité | Éternité |
| Base 85(alphabet étendu + spéciaux) | 24 jours | 2,93e+6 années | Éternité | Éternité |
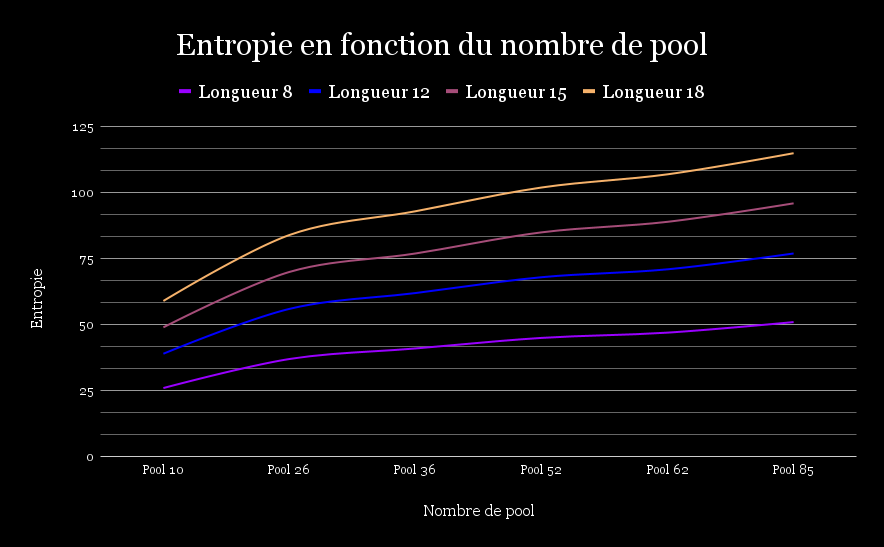
Pour mieux comprendre les tableaux précédents et différencier l'importance des deux paramètres B (nombre de pool) et L (nombre de caractères), nous avons séparé l'évolution de l'entropie en deux graphiques respectifs. Le premier affiche l'évolution de l'entropie en fonction de la taille du pool utilisé pour une longueur fixe donnée. Le second montre l'évolution de l'entropie en fonction de la longueur du mot de passe pour un pool fixé.
Sur ce premier graphique, on observe que, quelle que soit la longueur du mot de passe, l'entropie augmente toujours lorsque le nombre de caractères possibles dans le pool augmente.
De plus, on constate que les courbes associées aux longueurs plus élevées sont systématiquement au-dessus des autres.
L'écart entre les courbes s'accentue lorsque le pool devient plus grand, montrant un effet cumulatif entre longueur et diversité des caractères.
Sur ce second graphique, on constate que, de la même manière, pour tous les pools fixés, l'entropie augmente de manière quasi linéaire avec la longueur du mot de passe. Chaque caractère supplémentaire rajouté à un mot de passe apporte un gain significatif en sécurité, surtout lorsque le pool est important.
De plus, on observe aussi que les courbes associées aux pools plus élevés sont toujours au-dessus des autres, démontrant encore l'importance de ce paramètre.
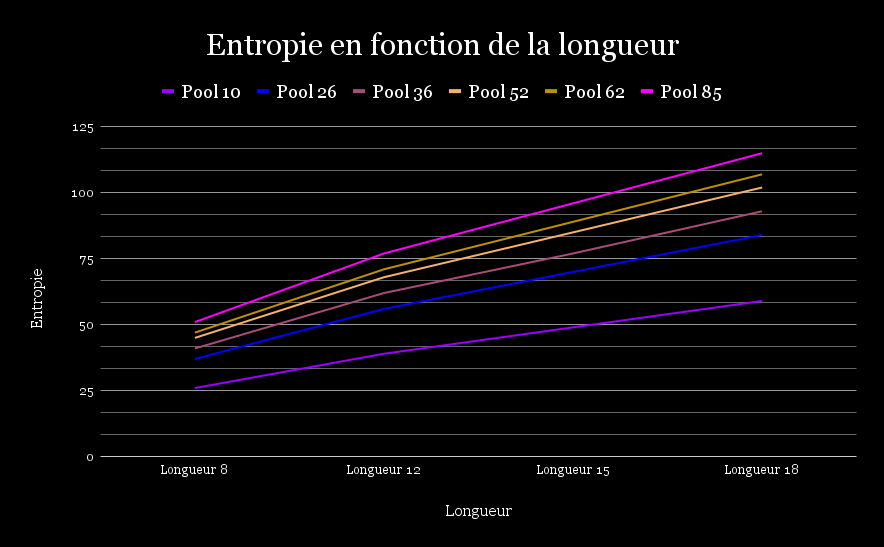
Ces deux graphiques montrent clairement que la sécurité d'un mot de passe repose principalement sur deux facteurs : sa longueur et la diversité des caractères utilisés. L'augmentation de l'un ou de l'autre améliore l'entropie, mais c'est leur combinaison qui produit le gain le plus important. Ainsi, pour créer des mots de passe réellement robustes, il est recommandé d'utiliser des mots de passe longs, composés d'un large éventail de caractères (lettres minuscules et majuscules, chiffres et symboles). Cette approche permet de rendre les attaques par force brute et par dictionnaire beaucoup plus difficiles, voire irréalistes en pratique.
De ces éléments, on peut tirer trois propriétés fondamentales d'un mot de passe robuste :